
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- List Comprehension
- pythonML
- 준비
- context manger1
- teen learn
- 시험 일정
- matplotlib
- K 데이터 자격시험
- 검정수수료
- Seaborn
- numpy
- separating data(데이터 분리하기)
- 응시료
- 빅데이터 분석기사
- Today
- Total
재원's 블로그
python text maining (R) 본문
최초 작성일 : 2021-12-15
categories: R
<개요>
-빅데이터 분석 및 시각화 & 텍스트 마이닝
- Ref-01 [Matplotlib-histogram 그리기][https://wikidocs.net/92112]
- Ref-02 [딥 러닝을 이용한 자연어 처리 입문-네이버 쇼핑 리뷰 감성 분류하기][https://wikidocs.net/94600]
<평가>
- 다음은 네이버 쇼핑 리뷰 감성 분류하기 예제입니다.
- 빈칸에 # 코드 입력란에 적당한 코드를 작성하시기를 바랍니다.
- 각 빈칸당 10점입니다.
<Colab에 Mecab 설치>
# Colab에 Mecab 설치
!git clone https://github.com/SOMJANG/Mecab-ko-for-Google-Colab.git
%cd Mecab-ko-for-Google-Colab
!bash install_mecab-ko_on_colab190912.sh
<네이버 쇼핑 리뷰 데이터에 대한 이해와 전처리>
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import urllib.request
from collections import Counter
from konlpy.tag import Mecab
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
<데이터 불러오기>
urllib.request.urlretrieve("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt", filename="ratings_total.txt")
- 해당 데이터에는 열 제목이 별도로 없음. 그래서 임의로 두 개의 열제목인 “ratings”와 “reviews” 추가
# (1) 데이터 불러오고, 전체 리뷰 개수 출력 # 200,000
totalDt = pd.read_table('ratings_total.txt', names=['ratings', 'reviews'])
print('전체 리뷰 개수 :',len(totalDt)) # 전체 리뷰 개수 출력
<실행 화면>
전체 리뷰 개수 : 200000
totalDt[:5] #리뷰 5개만 보여줌.
<훈련 데이터와 테스트 데이터 분리하기>
totalDt['label'] = np.select([totalDt.ratings > 3], [1], default=0)
totalDt[:5]
<각 열에 대해서 중복을 제외한 샘플의 수 카운트>
totalDt['ratings'].nunique(), totalDt['reviews'].nunique(), totalDt['label'].nunique()
<실행 화면>
(4, 199908, 2)
- ratings열의 경우 1, 2, 4, 5라는 네 가지 값을 가지고 있습니다.
reviews열에서 중복을 제외한 경우 199,908개입니다.
현재 20만개의 리뷰가 존재하므로 이는 현재 갖고 있는 데이터에 중복인 샘플들이 있다는 의미입니다.
중복인 샘플들을 제거해줍니다.
# (2) review열에서 중복 데이터 제거 drop_duplicates() 함수 활용
totalDt.drop_duplicates(subset=['reviews'], inplace=True)
print('총 샘플의 수 :',len(totalDt))
<실행 화면>
총 샘플의 수 : 199908
<NULL 값 유무 확인>
print(totalDt.isnull().values.any())
<실행 화면>
False
<훈련 데이터와 테스트 데이터를 3:1 비율로 분리>
train_data, test_data = train_test_split(totalDt, test_size = 0.25, random_state = 42)
print('훈련용 리뷰의 개수 :', len(train_data))
print('테스트용 리뷰의 개수 :', len(test_data))
<실행 화면>
훈련용 리뷰의 개수 : 149931
테스트용 리뷰의 개수 : 49977
<레이블의 분포 확인>
# (3) label 1, 0 막대그래프 그리기
import matplotlib.pyplot as plt
import numpy as np
fig, ax = plt.subplots(1,1,figsize=(7,5))
width = 0.15
plot_Dt= train_data['label'].value_counts().plot(kind = 'bar', color='orange', edgecolor='black').legend()
plt.title('train_data',fontsize=20) ## 타이틀 출력
plt.ylabel('Count',fontsize=10) ## y축 라벨 출력
plt.show()
<실행 화면>
print(train_data.groupby('label').size().reset_index(name = 'count'))
<실행 화면>
label count
0 0 74918
1 1 75013
- 두 레이블 모두 약 7만 5천개로 50:50 비율을 가짐
<데이터 정제하기>
정규 표현식을 사용하여 한글을 제외하고 모두 제거해줍니다.
# 한글과 공백을 제외하고 모두 제거 # (4) 한글 및 공백 제외한 모든 글자 제거 train_data['reviews'] = train_data['reviews'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","") train_data['reviews'].replace('', np.nan, inplace=True) print(train_data.isnull().sum())<실행 화면>
ratings 0 reviews 0 label 0 dtype: int64테스트 데이터에 대해서도 같은 과정을 거칩니다.
# (5) 데스트 데이터에 적용하기 # 코드 1 중복 제거 # 코드 2 정규 표현식 수행 # 코드 3 공백은 Null 값으로 변경 # 코드 4 Null 값 제거 test_data.drop_duplicates(subset = ['reviews'], inplace=True) # 중복 제거 test_data['reviews'] = test_data['reviews'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","") # 정규 표현식 수행 test_data['reviews'].replace('', np.nan, inplace=True) # 공백은 Null 값으로 변경 test_data = test_data.dropna(how='any') # Null 값 제거 print('전처리 후 테스트용 샘플의 개수 :',len(test_data))<실행 화면>
전처리 후 테스트용 샘플의 개수 : 49977<토큰화>
형태소 분석기 Mecab을 사용하여 토큰화 작업을 수행한다.
# (6) Mecab 클래스 호출하기 mecab = Mecab() print(mecab.morphs('와 이런 것도 상품이라고 차라리 내가 만드는 게 나을 뻔'))<실행 화면>
['와', '이런', '것', '도', '상품', '이', '라고', '차라리', '내', '가', '만드', '는', '게', '나을', '뻔']불용어를 지정하여 필요없는 토큰들을 제거하도록 한다.
# (7) 불용어 만들기 stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']훈련 데이터와 테스트 데이터에 대해서 동일한 과정을 거친다.
train_data['tokenized'] = train_data['reviews'].apply(mecab.morphs) train_data['tokenized'] = train_data['tokenized'].apply(lambda x: [item for item in x if item not in stopwords])test_data['tokenized'] = test_data['reviews'].apply(mecab.morphs) test_data['tokenized'] = test_data['tokenized'].apply(lambda x: [item for item in x if item not in stopwords])<단어와 길이 분포 확인하기>
긍정 리뷰에는 주로 어떤 단어들이 많이 등장하고, 부정 리뷰에는 주로 어떤 단어들이 등장하는지
두 가지 경우에 대해서 각 단어의 빈도수를 계산해보겠습니다.
각 레이블에 따라서 별도로 단어들의 리스트를 저장해줍니다.negative_W = np.hstack(train_data[train_data.label == 0]['tokenized'].values) positive_W = np.hstack(train_data[train_data.label == 1]['tokenized'].values) negative_W positive_W<실행 화면>
array(['적당', '만족', '합니다', ..., '잘', '삿', '어요'], dtype='<U25')Counter()를 사용하여 각 단어에 대한 빈도수를 카운트한다.
우선 부정 리뷰에 대해서 빈도수가 높은 상위 20개 단어 출력
negative_word_count = Counter(negative_W)
print(negative_word_count.most_common(20))
<실행 화면>
[('네요', 31799), ('는데', 20295), ('안', 19718), ('어요', 14849), ('있', 13200), ('너무', 13058), ('했', 11783), ('좋', 9812), ('배송', 9677), ('같', 8997), ('구매', 8876), ('어', 8869), ('거', 8854), ('없', 8670), ('아요', 8642), ('습니다', 8436), ('그냥', 8355), ('되', 8345), ('잘', 8029), ('않', 7984)]
- ‘네요’, ‘는데’, ‘안’, ‘않’, ‘너무’, ‘없’ 등과 같은 단어들이 부정 리뷰에서 주로 등장합니다.
긍정 리뷰에 대해서도 동일하게 출력해봅시다.
<실행 화면>positive_word_count = Counter(positive_W) print(positive_word_count.most_common(20))[('좋', 39488), ('아요', 21184), ('네요', 19895), ('어요', 18686), ('잘', 18602), ('구매', 16171), ('습니다', 13320), ('있', 12391), ('배송', 12275), ('는데', 11670), ('했', 9818), ('합니다', 9801), ('먹', 9635), ('재', 9273), ('너무', 8397), ('같', 7868), ('만족', 7261), ('거', 6482), ('어', 6294), ('쓰', 6292)] - 좋’, ‘아요’, ‘네요’, ‘잘’, ‘너무’, ‘만족’ 등과 같은
단어들이 주로 많이 등장합니다.
두 가지 경우에 대해서 각각 길이 분포를 확인해봅시다.
```python(8) 긍정 리뷰와 부정 리뷰 히스토그램 작성하기
fig,(ax1,ax2) = plt.subplots(1,2,figsize=(9,5))
text_len = train_data[train_data['label']==1]['tokenized'].map(lambda x: len(x))
ax1.hist(text_len, color='pink', edgecolor='black')
ax1.set_title('Positive Reviews')
ax1.set_xlabel('length of samples')
ax1.set_ylabel('number of samples')
print('긍정 리뷰의 평균 길이 :', np.mean(text_len))
text_len = train_data[train_data['label']==0]['tokenized'].map(lambda x: len(x))
ax2.hist(text_len, color='skyblue', edgecolor='black')
ax2.set_title('부정 리뷰')
ax2.set_title('Negative Reviews')
fig.suptitle('Words in texts')
ax2.set_xlabel('length of samples')
ax2.set_ylabel('number of samples')
print('부정 리뷰의 평균 길이 :', np.mean(text_len))
plt.show()
<실행 화면>
```python
긍정 리뷰의 평균 길이 : 13.5877381253916
부정 리뷰의 평균 길이 : 17.02948557089084
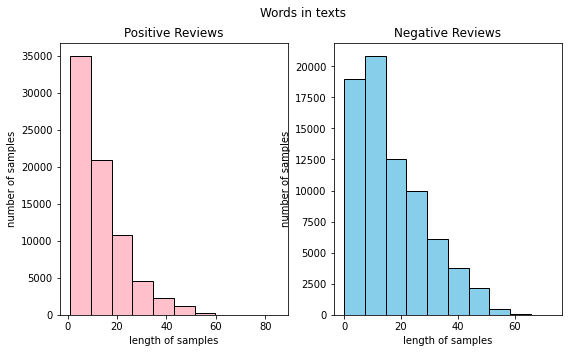
- 긍정 리뷰보다는 부정 리뷰가 좀 더 길게 작성된 경향이 있는 것 같다.
X_train = train_data['tokenized'].values
y_train = train_data['label'].values
X_test= test_data['tokenized'].values
y_test = test_data['label'].values
<정수 인코딩>
- 이제 기계가 텍스트를 숫자로 처리할 수 있도록 훈련 데이터와 테스트 데이터에 정수 인코딩을 수행해야 합니다.
우선, 훈련 데이터에 대해서 단어 집합(vocaburary)을 만들어봅시다.# (9) 정수 인코딩 클래스 호출 및 X_train 데이터에 적합하기 tokenizer = Tokenizer() tokenizer.fit_on_texts(X_train) - 단어 집합이 생성되는 동시에 각 단어에 고유한 정수가 부여되었습니다.
이는 tokenizer.word_index를 출력하여 확인 가능합니다.
등장 횟수가 1회인 단어들은 자연어 처리에서 배제하고자 합니다.
이 단어들이 이 데이터에서 얼만큼의 비중을 차지하는지 확인해봅시다.
```python
threshold = 2
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt)*100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq)*100)
<실행 화면>
```python
단어 집합(vocabulary)의 크기 : 39998
등장 빈도가 1번 이하인 희귀 단어의 수: 18213
단어 집합에서 희귀 단어의 비율: 45.53477673883694
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 0.7935698749320282
단어가 약 40,000개가 존재합니다. 등장 빈도가 threshold 값인 2회 미만.
즉, 1회인 단어들은 단어 집합에서 약 45%를 차지합니다.
하지만, 실제로 훈련 데이터에서 등장 빈도로 차지하는 비중은 매우 적은 수치인 약 0.8%밖에 되지 않습니다.
아무래도 등장 빈도가 1회인 단어들은 자연어 처리에서 별로 중요하지 않을 듯 합니다.
그래서 이 단어들은 정수 인코딩 과정에서 배제시키겠습니다.등장 빈도수가 1인 단어들의 수를 제외한 단어의 개수를 단어 집합의 최대 크기로 제한하겠습니다.
# 전체 단어 개수 중 빈도수 2이하인 단어 개수는 제거.
# 0번 패딩 토큰과 1번 OOV 토큰을 고려하여 +2
vocab_size = total_cnt - rare_cnt + 2
print('단어 집합의 크기 :',vocab_size)
<실행 화면>
단어 집합의 크기 : 21787
- 이제 단어 집합의 크기는 21,787개입니다. 이를 토크나이저의 인자로 넘겨주면, 토크나이저는 텍스트 시퀀스를 숫자 시퀀스로 변환합니다.
이러한 정수 인코딩 과정에서 이보다 큰 숫자가 부여된 단어들은 OOV로 변환하겠습니다.
```python(10) 토크나이저 클래스 호출 및 OOV 변환 코드 작성
코드 1
코드 2
tokenizer = Tokenizer(vocab_size, oov_token = 'OOV')
tokenizer.fit_on_texts(X_train)
X_train = tokenizer.texts_to_sequences(X_train)
X_test = tokenizer.texts_to_sequences(X_test)
- 정수 인코딩이 진행되었는지 확인하고자 X_train과 X_test에 대해서 상위 3개의 샘플만 출력합니다.
```python
print(X_train[:3])
<실행 화면>
[[67, 2060, 299, 14259, 263, 73, 6, 236, 168, 137, 805, 2951, 625, 2, 77, 62, 207, 40, 1343, 155, 3, 6], [482, 409, 52, 8530, 2561, 2517, 339, 2918, 250, 2357, 38, 473, 2], [46, 24, 825, 105, 35, 2372, 160, 7, 10, 8061, 4, 1319, 29, 140, 322, 41, 59, 160, 140, 7, 1916, 2, 113, 162, 1379, 323, 119, 136]]
print(X_test[:3])
<실행 화면>
[[14, 704, 767, 116, 186, 252, 12], [339, 3904, 62, 3816, 1651], [11, 69, 2, 49, 164, 3, 27, 15, 6, 1, 513, 289, 17, 92, 110, 564, 59, 7, 2]]
<패딩>
이제 서로 다른 길이의 샘플들의 길이를 동일하게 맞춰주는 패딩 작업을 진행해보겠습니다.
전체 데이터에서 가장 길이가 긴 리뷰와 전체 데이터의 길이 분포를 알아보겠습니다.print('리뷰의 최대 길이 :',max(len(l) for l in X_train)) print('리뷰의 평균 길이 :',sum(map(len, X_train))/len(X_train)) plt.hist([len(s) for s in X_train], bins=35, label='bins=35', color="skyblue") plt.xlabel('length of samples') plt.ylabel('number of samples') plt.show()<실행 화면>
리뷰의 최대 길이 : 85 리뷰의 평균 길이 : 15.307521459871541
리뷰의 최대 길이는 85, 평균 길이는 약 15입니다.
그리고 그래프로 봤을 때, 전체적으로는 60이하의 길이를 가지는 것으로 보입니다.
def below_threshold_len(max_len, nested_list):
count = 0
for sentence in nested_list:
if(len(sentence) <= max_len):
count = count + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (count / len(nested_list))*100))
- 최대 길이가 85이므로 만약 80으로 패딩할 경우, 몇 개의 샘플들을 온전히 보전할 수 있는지 확인해봅시다.
<실행 화면>max_len = 80 below_threshold_len(max_len, X_train)전체 샘플 중 길이가 80 이하인 샘플의 비율: 99.99933302652553 - 훈련용 리뷰의 99.99%가 80이하의 길이를 가집니다.
훈련용 리뷰를 길이 80으로 패딩하겠습니다.
<GRU로 네이버 쇼핑 리뷰 감성 분류 하기>X_train = pad_sequences(X_train, maxlen = max_len) X_test = pad_sequences(X_test, maxlen = max_len)
```python
from tensorflow.keras.layers import Embedding, Dense, GRU
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
embedding_dim = 100
hidden_units = 128
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(GRU(hidden_units))
model.add(Dense(1, activation='sigmoid'))
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('best_model.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(X_train, y_train, epochs=15, callbacks=[es, mc], batch_size=64, validation_split=0.2)
def sentiment_predict(new_sentence):
new_sentence = re.sub(r'[^ㄱ-ㅎㅏ-ㅣ가-힣 ]','', new_sentence)
new_sentence = mecab.morphs(new_sentence) # 토큰화
new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거
encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩
score = float(model.predict(pad_new)) # 예측
if(score > 0.5):
print("{:.2f}% 확률로 긍정 리뷰입니다.".format(score * 100))
else:
print("{:.2f}% 확률로 부정 리뷰입니다.".format((1 - score) * 100))
<실행 화면>
```python
Epoch 1/15
1875/1875 [==============================] - ETA: 0s - loss: 0.2725 - acc: 0.8967
Epoch 00001: val_acc improved from -inf to 0.91916, saving model to best_model.h5
1875/1875 [==============================] - 54s 25ms/step - loss: 0.2725 - acc: 0.8967 - val_loss: 0.2301 - val_acc: 0.9192
Epoch 2/15
1875/1875 [==============================] - ETA: 0s - loss: 0.2158 - acc: 0.9213
Epoch 00002: val_acc improved from 0.91916 to 0.92240, saving model to best_model.h5
1875/1875 [==============================] - 43s 23ms/step - loss: 0.2158 - acc: 0.9213 - val_loss: 0.2137 - val_acc: 0.9224
Epoch 3/15
1875/1875 [==============================] - ETA: 0s - loss: 0.1985 - acc: 0.9289
Epoch 00003: val_acc improved from 0.92240 to 0.92637, saving model to best_model.h5
1875/1875 [==============================] - 44s 24ms/step - loss: 0.1985 - acc: 0.9289 - val_loss: 0.2060 - val_acc: 0.9264
Epoch 4/15
1873/1875 [============================>.] - ETA: 0s - loss: 0.1878 - acc: 0.9332
Epoch 00004: val_acc did not improve from 0.92637
1875/1875 [==============================] - 43s 23ms/step - loss: 0.1878 - acc: 0.9332 - val_loss: 0.2031 - val_acc: 0.9260
Epoch 5/15
1874/1875 [============================>.] - ETA: 0s - loss: 0.1783 - acc: 0.9369
Epoch 00005: val_acc improved from 0.92637 to 0.92670, saving model to best_model.h5
1875/1875 [==============================] - 46s 24ms/step - loss: 0.1783 - acc: 0.9369 - val_loss: 0.2030 - val_acc: 0.9267
Epoch 6/15
1873/1875 [============================>.] - ETA: 0s - loss: 0.1698 - acc: 0.9405
Epoch 00006: val_acc improved from 0.92670 to 0.92764, saving model to best_model.h5
1875/1875 [==============================] - 44s 24ms/step - loss: 0.1697 - acc: 0.9405 - val_loss: 0.2055 - val_acc: 0.9276
Epoch 7/15
1873/1875 [============================>.] - ETA: 0s - loss: 0.1611 - acc: 0.9436
Epoch 00007: val_acc did not improve from 0.92764
1875/1875 [==============================] - 44s 24ms/step - loss: 0.1610 - acc: 0.9437 - val_loss: 0.2098 - val_acc: 0.9244
Epoch 8/15
1875/1875 [==============================] - ETA: 0s - loss: 0.1526 - acc: 0.9473
Epoch 00008: val_acc did not improve from 0.92764
1875/1875 [==============================] - 44s 23ms/step - loss: 0.1526 - acc: 0.9473 - val_loss: 0.2269 - val_acc: 0.9189
Epoch 9/15
1875/1875 [==============================] - ETA: 0s - loss: 0.1435 - acc: 0.9507
Epoch 00009: val_acc did not improve from 0.92764
1875/1875 [==============================] - 44s 24ms/step - loss: 0.1435 - acc: 0.9507 - val_loss: 0.2258 - val_acc: 0.9204
Epoch 00009: early stopping
sentiment_predict('이 상품 진짜 싫어요... 교환해주세요')
<실행 화면>
99.03% 확률로 부정 리뷰입니다.
sentiment_predict('이 상품 진짜 좋아여... 강추합니다. ')
<실행 화면>
99.51% 확률로 긍정 리뷰입니다.
'R' 카테고리의 다른 글
| R-text maining3 (0) | 2023.01.23 |
|---|---|
| R-Text Mining2(R-텍스트 마이닝2) (0) | 2023.01.23 |
| R-Text Mining1(R-텍스트 마이닝1) (0) | 2023.01.23 |
| R data cleaning method('R' 데이터 정제 방법) (0) | 2023.01.20 |